
Les chercheurs du laboratoire CSAIL du MIT ont récemment développé une méthode novatrice d'entraînement pour les réseaux de neurones, appelée Diffusion Forcing. Cette technique fusionne deux approches bien établies en intelligence artificielle : la prédiction de séquences et la diffusion d'images. Cette combinaison permet aux robots d'interpréter des données visuelles altérées et de prédire avec précision les étapes futures d'une tâche. Initialement, les modèles de prédiction de séquences, comme ceux utilisés dans ChatGPT, fonctionnent en analysant chaque élément successif (token) sans tenir compte des actions éloignées, tandis que les modèles de diffusion excellent dans la génération de séquences visuelles, mais ont des difficultés à adapter la longueur des séquences aux besoins spécifiques de chaque tâche.
Avec cette fusion, le Diffusion Forcing offre une flexibilité accrue pour les applications en vision par ordinateur et planification robotique. En associant prédiction de jetons et modèles de diffusion, cette méthode vise à prolonger la génération de séquences de manière stable, répondant aux exigences de diverses applications, notamment la génération vidéo et la planification de trajectoires.
Surmonter les limites des modèles de séquence actuels
Les modèles séquentiels actuels, qu'ils soient dédiés aux flux vidéo ou à de longs textes, peinent souvent à maintenir stabilité et cohérence au fil du temps. Les modèles de prédiction de prochain jeton, comme ceux utilisés dans les modèles de langage, sont performants pour générer du texte ou des actions de façon dynamique, mais se révèlent limités pour des prévisions continues. En parallèle, les modèles de diffusion offrent des résultats efficaces pour des séquences de longueur fixe, mais leur manque de causalité limite leur adaptabilité dans des contextes où les données évoluent.
La méthode Diffusion Forcing propose une solution en intégrant un processus de diffusion contrôlé et adaptable, offrant ainsi des séquences longues et stables. Ce modèle hybride, dénommé Causal Diffusion Forcing (CDF), ajuste le niveau de bruit appliqué à chaque élément de la séquence en fonction des étapes précédentes, garantissant une continuité sans la dérive souvent observée dans les modèles de diffusion traditionnels.
Un modèle hybride pour la stabilité à long terme
Au cœur de l’approche Diffusion Forcing se trouve une combinaison de prédiction séquentielle de jetons et d’un processus de diffusion qui gère le bruit sur les séquences de données. Concrètement, chaque jeton est généré avec un niveau de bruit spécifique, ajusté pour s’aligner avec l’ensemble de la séquence. Ce procédé permet de générer des séquences où chaque élément s’influence mutuellement, tout en maintenant une flexibilité et une stabilité même sur des horizons temporels étendus.
Pour implémenter cette technique, les chercheurs ont conçu le modèle CDF, qui adapte le bruit appliqué aux jetons en tenant compte du contexte séquentiel. Cette approche assure la continuité des prévisions, en particulier dans des scénarios de planification robotique et de génération vidéo, où la précision et la stabilité des séquences sont essentielles.
Applications en génération vidéo et planification de trajectoire
Le potentiel de cette approche est particulièrement prometteur pour des domaines tels que la génération vidéo et la planification de trajectoires en robotique. Dans le domaine de la vidéo, CDF assure une stabilité de génération, permettant de produire des séquences longues sans perte de cohérence. Contrairement aux modèles de diffusion traditionnels qui partent d’une image initiale fixe pour générer la séquence complète, CDF adapte la génération à chaque étape, garantissant ainsi une continuité fluide dans les mouvements et l’apparence des objets.
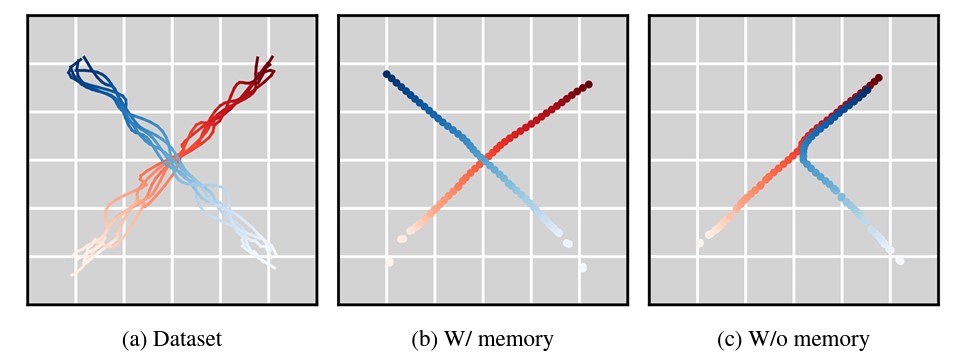
Génération de trajectoires avec et sans mémoire • Source : Boyuan Chen et al.
Pour la planification de trajectoires, cette technologie trouve une application dans les systèmes de prise de décision, notamment en navigation autonome. En combinant une méthode dite Monte Carlo Tree Guidance (MCTG), le modèle CDF oriente la génération de séquences vers les trajectoires maximisant les chances de succès dans des tâches de renforcement. Par exemple, dans un environnement de labyrinthe, cette méthode aide un agent à adapter sa trajectoire en temps réel pour atteindre sa cible de manière optimale.
Performances et comparaisons avec les méthodes traditionnelles
Les chercheurs du MIT ont observé une nette amélioration des performances du modèle CDF par rapport aux méthodes de diffusion classiques. Lors de tests, CDF a réduit significativement les erreurs de trajectoire (mesurées par l’average displacement error, ou ADE) et amélioré la précision avec un faible taux d’erreur de calibration (ou normalized calibration error, NCE). Contrairement aux modèles Gaussiens qui montrent une dérive sur de longues séquences, CDF maintient une trajectoire stable même au-delà des horizons d’entraînement.
Ces résultats, validés sur plusieurs environnements de test, indiquent que l'approche hybride CDF permet une gestion plus maîtrisée de l'incertitude dans des prévisions critiques, notamment en robotique et en prévision météorologique, deux domaines où la précision des séquences est cruciale.
Applications concrètes : robotique et prise de décision
L'une des applications de CDF concerne la manipulation d'objets par des robots, où la méthode a démontré sa capacité à accomplir des tâches même en présence de distractions visuelles. Par exemple, un robot guidé par Diffusion Forcing a été capable de placer des objets dans des emplacements précis malgré des obstacles visuels. Outre la manipulation d'objets, cette technique permet aussi de générer des vidéos stables et de prendre des décisions dans des environnements numériques.
Lors de plusieurs expériences, CDF a surpassé d'autres modèles en termes de stabilité et de cohérence visuelle. En partant d’une seule image initiale, CDF a généré des vidéos de meilleure qualité que les modèles de diffusion standards, démontrant son potentiel pour des applications en simulation vidéo et dans le divertissement.
Vers des robots apprenant par l'observation
Un objectif à long terme pour les chercheurs est de transformer CDF en un “world model” capable de simuler les dynamiques de l’environnement en s’appuyant sur les vastes collections de vidéos en ligne. Un tel modèle permettrait aux robots d’apprendre de nouvelles tâches par simple observation, sans intervention humaine. Par exemple, un robot pourrait reproduire l’action d’ouvrir une porte en observant une vidéo de démonstration, même sans entraînement spécifique. Récemment, la start-up World Labs - créée par la pionnière de l'IA Fei-Fei Li - a levé 230 millions de dollars (215 M€) pour créer des large world models.
Les perspectives d’amélioration de CDF incluent notamment l’intégration d'autres techniques de diffusion et l'ajustement du niveau de bruit en fonction du contexte. Cette technologie pourrait également trouver des applications dans la simulation de trafic et la gestion de flux en temps réel, des domaines où la prévision des événements avec précision est primordiale.
Une voie vers une IA plus prédictive et adaptable
En combinant les avantages des modèles de diffusion et de prédiction séquentielle, Diffusion Forcing pourrait devenir un cadre de référence pour les applications de génération de séquences. Qu’il s’agisse de simulation en IA, de génération vidéo ou de planification d’actions en temps réel, cette approche permet à l'IA de naviguer dans des environnements complexes avec une fiabilité accrue.
À terme, les chercheurs du MIT envisagent d’étendre cette technologie aux grands ensembles de données et aux modèles de type transformateur les plus récents. Leur ambition ultime est de créer une sorte de "cerveau de robot" inspiré de ChatGPT, permettant aux robots de s’adapter aux environnements inconnus sans intervention humaine directe.
Pour en savoir plus :
- Boyuan Chen et al., Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion, Arxiv, 2024
- MIT
- Photonics