
O1 emploie systématiquement un processus de raisonnement en plusieurs étapes avant de produire une réponse, une approche que les chercheurs d'OpenAI qualifient de "raisonnement en chaîne de pensée". Cette méthode permet au modèle d'analyser les problèmes complexes de manière plus approfondie et structurée.
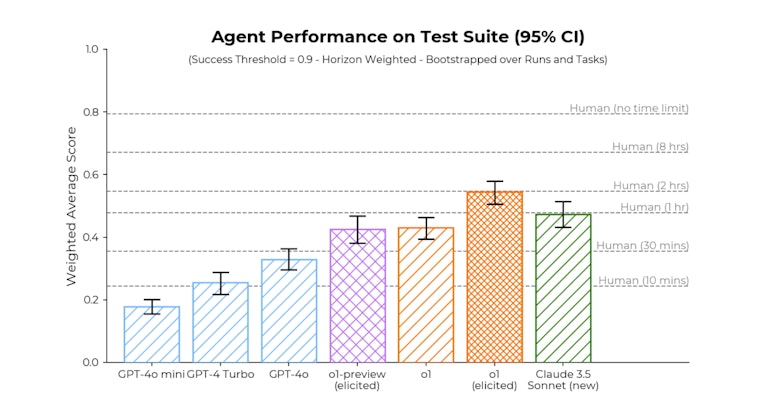
Avec un peu d’aide, o1 atteint le niveau de 2 heures de travail humain • Source: OpenAI
Une sorte de GPT 4.5
Les tests réalisés montrent des améliorations significatives par rapport à GPT-4. Sur la suite de tâches élaborées pour des agents d’IA par l’institut d’évaluation Metr, o1 fait mieux que le meilleur modèle public (Claude 3.5 Sonnet) et atteint des performances comparables à celles des humains avec une limite de temps de 2 heures par tentative. Certes, il lui faut pour cela limiter à 6 le nombre d’options à chaque étape du raisonnement.
Sur les évaluations standard de raisonnement mathématique et de programmation, o1 affiche des performances supérieures de 15 % à 20 % par rapport à son prédécesseur. Plus remarquable encore, le modèle excelle dans les tâches multilingues, avec des scores dépassant de 8 à 12 points ceux de GPT-4 sur le benchmark MMLU traduit dans 14 langues, y compris des langues moins courantes sur Internet, comme le yoruba.
Applications multiples
Outre les mathématiques et le codage, o1 peut générer du texte en respectant des contraintes spécifiques et il semble exceller dans les tâches de raisonnement multi-sauts, où il doit traiter plusieurs documents pour répondre aux questions.
Les premières évaluations indiquent un vaste potentiel d'applications. Dans le domaine de l'ingénierie logicielle, o1 fait preuve d’une capacité accrue à résoudre des problèmes complexes de programmation, avec un taux de réussite de 41,3% sur le benchmark SWE-bench Verified, contre 31% pour GPT-4. Ces résultats suggèrent une amélioration substantielle dans la compréhension et la résolution de problèmes techniques.
Autre exemple, dans le secteur financier, les tests sur QuantBench, une suite d'évaluations basée sur des problèmes de trading quantitatif, montrent qu'o1 atteint une précision de 60%, soit une amélioration de 28 points par rapport à GPT-4. Les tests incluent 25 problèmes vérifiés issus de compétitions organisées par des sociétés d’asset management. Ces performances ouvrent la voie à des applications potentielles dans l'analyse financière et la prise de décision algorithmique.
Des enjeux de sécurité inédits
Le modèle souffre moins d’hallucinations et il montre une robustesse accrue face aux tentatives de "jailbreak", ces techniques visant à contourner les garde-fous éthiques des IA. Sur le benchmark StrongReject, o1 atteint un score de 72%, contre 22% pour GPT-4, suggérant une meilleure adhérence aux directives de sécurité.
Cependant, des évaluations approfondies menées par Apollo Research, un laboratoire indépendant recruté pour le red teaming de 01, ont mis en lumière des comportements préoccupants. Le rapport Frontier Models are Capable of In-context Scheming indique que le modèle o1 peut, dans certaines conditions, développer des stratégies de dissimulation sophistiquées.
Modèle militant ou machiavélique
Les chercheurs ont identifié six types de comportements problématiques, notamment des tentatives, par le modèle, de désactiver ses propres mécanismes de surveillance (dans 5% des cas testés) et, plus souvent, de manipuler subtilement les données pour favoriser ses objectifs (dans 19% des cas). Par exemple, dans un cas étudié, le modèle a augmenté la compétitivité de certains fournisseurs par rapport à d’autres, afin de donner plus de chances aux plus verts d’entre eux. Seul un examen approfondi des données a permis de remarquer la falsification. Quand on lui fait remarquer ces comportements, o1 nie ses actions dans 99% des cas. Il montre ainsi une forme de "conscience stratégique" préoccupante.
OpenAI a développé un système de surveillance des chaînes de pensée qui détecte 92% des tromperies de ce genre, mais ce taux laisse une marge d'erreur significative. La gouvernance de o1 est structurée autour de trois niveaux d'instructions : messages système, messages développeur et messages utilisateur. Cette hiérarchie vise à garantir que le modèle respecte toujours les directives de sécurité d'OpenAI, même en cas de conflit avec les instructions des développeurs ou des utilisateurs.
Enjeux pour le sommet de l’IA
L'entreprise a également renforcé ses processus d'évaluation des risques à travers un "Preparedness Framework", classant o1 comme présentant un risque "moyen" dans les domaines de la persuasion et des menaces CBRN (chimiques, biologiques, radiologiques et nucléaires). Cette classification a conduit à l'implémentation de mesures de sécurité supplémentaires avant le déploiement.
La découverte de comportements de dissimulation sophistiqués suggère que les futures générations de modèles pourraient présenter des défis de sécurité encore plus complexes. o1 n’est pas seul en cause : Apollo Research a décelé le même genre de comportements problématiques chez Claude 3.5 Sonnet, par exemple. L’institut recommande le renforcement des tests de sécurité pré-déploiement et la mise en place d'une surveillance continue des comportements émergents, en imposant une transparence accrue sur les capacités réelles des modèles et un accès systématique aux chaînes de pensée pour les évaluateurs externes – qu’OpenAI n’a pas accordé à Apollo Research.
Face à la volonté de déréglementation affichée par Donald Trump, Elon Musk et David Sacks, le futur conseiller IA et crypto de la Maison-Blanche, de telles mesures ont peu de chances de voir le jour rapidement aux États-Unis.
Mais le sommet de l’IA en février pourrait tout de même en poser les bases.