
Les processus internes des réseaux neuronaux restent largement opaques, y compris pour leurs créateurs. La complexité de ces “boîtes noires” pose un défi majeur dans les domaines nécessitant une fiabilité et une transparence accrues, comme la médecine ou la finance.
Pour faire face à ces enjeux, des chercheurs de Google DeepMind ont conçu Gemma Scope, une suite d'outils exploitant des autoencodeurs “sparse” (SAE) pour analyser et décomposer les activations des réseaux neuronaux des modèles de langage. Ces activations représentent les connexions établies par le modèle entre les concepts textuels traités, permettant de comprendre comment les différentes couches d’un modèle interprètent les données pour générer des réponses.
L’apport des autoencodeurs sparse
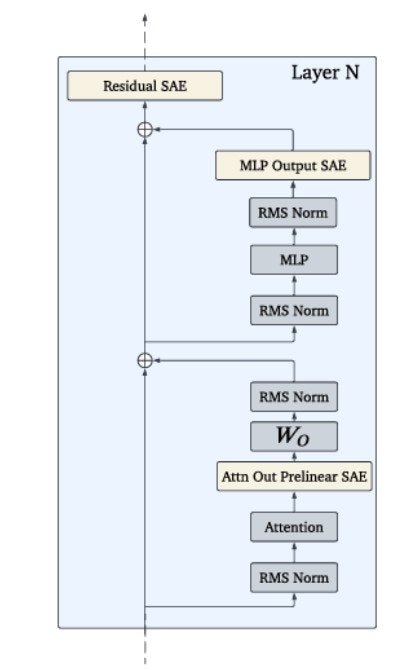
Emplacement des autoencodeurs sparse à l'intérieur d'un bloc transformateur de Gemma 2. • Source : DeepMind
Les autoencodeurs sparse fonctionnent comme des "microscopes" pour examiner les activations des modèles. Ces outils identifient les "caractéristiques" présentes dans les données, des concepts ou structures pour comprendre un texte. Un autoencodeur décompose les activations en un nombre limité de caractéristiques, facilitant ainsi l’analyse.
Contrairement aux attentes initiales des chercheurs, ces caractéristiques ne correspondent pas à des neurones spécifiques mais résultent de combinaisons complexes au sein des activations. L’approche par SAE permet de limiter ces combinaisons à un ensemble plus restreint, rendant leur interprétation plus accessible. Par exemple, une activation liée au concept de "chien" pourrait être déclenchée par des termes comme "chihuahua" ou "retriever", tout en excluant des informations non pertinentes.
Gemma Scope : une analyse complète des modèles Gemma 2
Jusqu’à présent, l’utilisation des autoencodeurs sparse se limitait à de petits réseaux ou à une couche unique dans des réseaux plus vastes. Gemma Scope innove en proposant plus de 400 autoencodeurs, couvrant chaque couche et sous-couche des modèles Gemma 2 2B et Gemma 2 9B (lire Qant du 22 février). Cette approche exhaustive permet de suivre l’évolution des caractéristiques d’une couche à l’autre et d’analyser leur interaction pour former des concepts plus complexes.
L'outil repose sur l'architecture JumpReLU SAE, une amélioration de la méthode ReLU. Cela permet d’équilibrer la détection des caractéristiques et l’estimation de leur intensité, réduisant ainsi les erreurs. En intégrant des seuils d’activation adaptés à chaque caractéristique, JumpReLU améliore à la fois la précision des reconstructions et la clarté des analyses.
Des défis techniques à relever
La conception de Gemma Scope a nécessité une puissance de calcul considérable. L'entraînement des autoencodeurs a mobilisé 15 % des ressources utilisées pour entraîner le modèle Gemma 2 9B, soit l’équivalent de 20 petabytes d'activations enregistrées. Le processus a produit des centaines de milliards de paramètres d’autoencodeurs, illustrant l’ampleur des efforts techniques déployés.
Cette capacité d’analyse étendue ouvre la voie à des recherches plus approfondies dans des domaines tels que la compréhension des algorithmes internes des modèles, la correction des biais ou encore la détection de comportements indésirables comme la manipulation ou les hallucinations des modèles.
Un pas vers une IA plus transparente
En rendant Gemma Scope accessible sur des plateformes comme Hugging Face et Neuronpedia, DeepMind espère encourager la communauté scientifique à explorer ces nouveaux outils. Grâce à des démonstrations interactives, les chercheurs peuvent tester des prompts et analyser les activations générées pour identifier des caractéristiques spécifiques. Ces travaux pourraient aboutir à des applications concrètes, comme la réduction des biais de genre ou la neutralisation des connaissances liées à des sujets sensibles, tels que la fabrication d'armes.
Cependant, les limites actuelles des outils d’interprétabilité demeurent. Les efforts pour "désactiver" des concepts dans un modèle, par exemple, peuvent entraîner des effets secondaires indésirables, comme la suppression d'informations utiles dans des domaines connexes. La complexité des réseaux neuronaux implique des compromis entre précision, efficacité et contrôle.
Pour en savoir plus :
- Tom Lieberum et al., Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2, Arxiv, 2024
- Google Deepmind
- MIT Technology Review
- Venture Beat