
Une équipe de chercheurs affiliés à l’université chinoise Fudan et au laboratoire d’intelligence artificielle de Shanghai vient de proposer un cadre méthodologique pour concevoir des modèles d’intelligence artificielle dotés de capacités de raisonnement avancé. Il se demande donc comment reproduire des LLM comme o1 d’OpenAI, en se concentrant sur une approche d'apprentissage par renforcement. Il détaille quatre composantes clés : l'initialisation de la politique, la conception de la récompense, la recherche et l'apprentissage. L'article examine différentes méthodes pour chacune de ces composantes, en analysant leurs forces et faiblesses, et en spéculant sur les techniques utilisées dans o1. Il passe en revue des projets open-source qui tentent de reproduire o1, les situant dans le cadre de cette feuille de route.
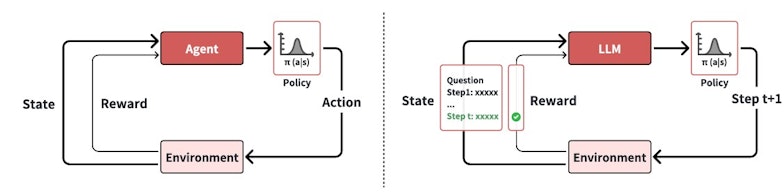
La visualisation de l'interaction entre l'agent et l'environnement dans l'apprentissage par renforcement pour les LLMs • Source : Zhiyuan Zeng et al.
L’apprentissage par renforcement : pilier de l’approche
L’apprentissage par renforcement repose sur la capacité d’un agent à interagir avec un environnement dynamique en ajustant ses décisions pour maximiser une récompense cumulative. Les chercheurs divisent le processus en quatre étapes structurées : l’initialisation des politiques, la définition des signaux de récompense, l’intégration de mécanismes de recherche et l’optimisation des stratégies d’apprentissage.
La première étape consiste à pré-entraîner les modèles sur des corpus textuels étendus. Cela leur permet d’acquérir des capacités de base telles que la compréhension linguistique, l’identification des tâches et une capacité limitée de raisonnement. Cette pré-formation est suivie par une phase d’affinement (fine-tuning) axée sur des instructions spécifiques, souvent guidée par des annotations humaines ou des modèles de référence. Cette méthode hybride améliore la précision et la pertinence des réponses des modèles dans des contextes diversifiés.
Les récompenses sont essentielles pour guider le comportement des modèles. Les chercheurs distinguent deux grandes catégories :
- Récompenses de résultat : elles évaluent exclusivement la qualité du produit final, par exemple la solution correcte à une équation ou une réponse cohérente à une question.
- Récompenses de processus : elles attribuent des points à chaque étape intermédiaire, récompensant ainsi des sous-objectifs atteints même si le résultat final est incorrect.
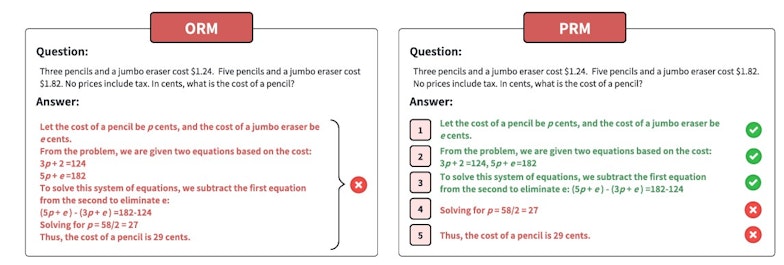
Récompense de résultat ou récompense de processus • Source : Zhiyuan Zeng et al.
Les récompenses de processus s’avèrent particulièrement efficaces pour des tâches impliquant plusieurs étapes critiques, comme le raisonnement mathématique ou les stratégies de jeu. Cependant, la rareté des signaux de récompense représente un défi, que les chercheurs tentent de résoudre grâce à des techniques comme le reward shaping, qui densifie les signaux en les adaptant à des micro-objectifs intermédiaires.
Recherche et optimisation : des mécanismes clés
La recherche active pendant l’entraînement et l’inférence constitue une autre innovation majeure. Les chercheurs expliquent comment des algorithmes tels que les arbres de Monte Carlo (MCTS) ou la recherche par faisceau (beam search) permettent de décomposer les tâches complexes en sous-étapes. Ces approches évaluent chaque branche d’un problème avant de sélectionner l’action optimale. Par exemple, un modèle chargé de résoudre un puzzle peut simuler différentes options avant de s’engager dans une solution.
Enfin, l'apprentissage utilise les données générées par la recherche pour améliorer la politique. Les données utilisées pour l'apprentissage sont issues de l'interaction du LLM avec l'environnement, éliminant ainsi le besoin d'une annotation coûteuse des données et ouvrant la voie à des performances surhumaines. L'apprentissage se fait via des méthodes de gradient de politique ou le clonage comportemental.
Le premier ajuste directement les probabilités d’actions optimales, tandis que le second imite les actions réussies observées pendant l’entraînement. Les méthodes de gradient de politique (policy gradient), comme REINFORCE, PPO et DPO, ont une utilisation élevée des données, tandis que le clonage de comportement est avantageux en termes de simplicité et d'efficacité de la mémoire.
En parallèle, des mécanismes de régulation, comme la pondération des erreurs ou la supervision par des experts humains, sont intégrés pour éviter que le modèle ne développe des biais ou des stratégies imprévues.
Défis techniques et solutions envisagées
Les auteurs identifient plusieurs obstacles à surmonter pour concrétiser les capacités de raisonnement avancé :
- Écart de distribution : Les modèles formés dans des environnements simulés peuvent rencontrer des difficultés lorsqu’ils sont déployés dans des contextes réels. Cet écart peut réduire leur efficacité et augmenter le risque d’erreurs critiques.
- Conception des récompenses granulaires : adapter les signaux de récompense à une diversité de tâches reste un problème complexe, notamment pour des applications exigeant une grande finesse, comme les diagnostics médicaux ou la finance.
Pour répondre à ces défis, les chercheurs proposent d’intégrer des modèles prédictifs simulant des environnements réels, aussi appelés world models. Ces modèles permettent de tester les performances des agents dans des contextes virtuels avant leur déploiement, réduisant ainsi l’écart entre la formation et l’utilisation réelle.
L’article examine plusieurs projets open source qui tentent de reproduire les capacités du modèle o1. Ces projets peuvent être considérés comme des composantes ou des cas spécifiques du cadre d'apprentissage par renforcement présenté par les chercheurs. Parmi ces modèles, on peut citer, parmi bien d’autres, G1 et Thinking Claude, qui utilisent le prompt engineering pour inciter un LLM à s'auto-évaluer et à proposer plusieurs solutions afin de cloner le comportement d'o1. Ou, plus proches du cadre présenté, Open-Reasoner et Slow Thinking with LLMs, qui utilisent l'apprentissage par renforcement pour améliorer les performances du modèle.
Les secrets derrière o1 et o3 • Source : Matthew Berman
Pour en savoir plus :
- Zhiyuan Zeng et al., Scaling of Search and Learning: A Roadmap to Reproduce o1 from Reinforcement Learning Perspective, Arxiv, 2024
