
Publié en fin d’année dernière, l’article Byte Latent Transformer: Patches Scale Better Than Token présente une nouvelle forme de modèle linguistique de grande taille (LLM) qui traite les données brutes en octets au lieu de jetons, améliorant ainsi l'efficacité et la robustesse. BLT regroupe dynamiquement les octets en « patches » de taille variable, allouant plus de ressources de calcul aux parties les plus complexes.
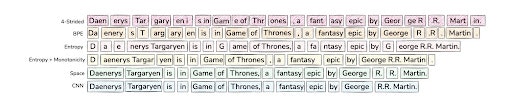
Création de tokens (1ère ligne) et de patches pour les BLT • Source : Artidoro Pagnoni et al.
Contrairement aux approches traditionnelles qui utilisent un découpage fixe en tokens, le BLT adapte la taille de ses unités de traitement - les patches - en fonction de l'entropie locale du texte. Cette adaptation dynamique permet une allocation optimisée des ressources computationnelles.
De plus, la tokenisation introduit des biais dans la façon dont une chaîne est compressée, ce qui peut entraîner des problèmes de sensibilité au domaine, de sensibilité au bruit d'entrée, de manque de connaissance orthographique et d'inégalité multilingue. En travaillant directement avec les octets, BLT évite ces limitations. Il permet également au modèle une compréhension “infralexicale”, au niveau de la lettre et non du mot.
Une architecture Transformer
L'architecture du BLT repose sur trois composants principaux interconnectés. L'encodeur local, premier élément de cette chaîne de traitement, convertit les séquences d'octets en représentations de patches. Le transformeur latent global, constituant le cœur du système, opère sur ces représentations. Ce modèle de langage autoregressif est le plus coûteux en calcul pendant le pré-entraînement et l'inférence. Enfin, le décodeur local assure la reconversion des représentations abstraites en séquences d'octets.
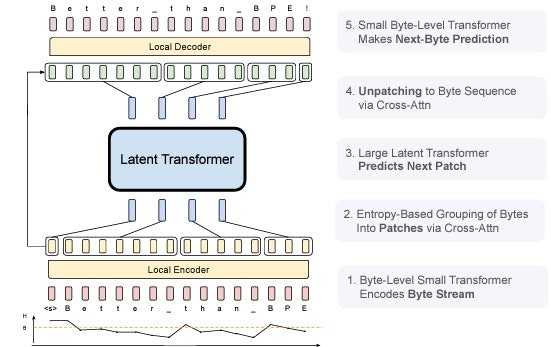
Fonctionnement du Byte Latent Transformer • Source : Artidoro Pagnoni et al.
La taille des patchs a un impact significatif sur l'efficacité et les performances du Byte Latent Transformer (BLT). Contrairement aux modèles basés sur la tokenisation qui allouent la même quantité de calcul à chaque token, BLT regroupe dynamiquement les octets en patchs de taille variable, ce qui permet une allocation plus efficace du calcul.
Le modèle sauve l’honneur
Les évaluations expérimentales démontrent des résultats plutôt probants. Testé sur des modèles allant jusqu'à 8 milliards de paramètres et entraîné sur 4 téraoctets de données, le BLT atteint des performances comparables aux LLM de référence, notamment Llama 3, tout en réduisant significativement les coûts de calcul.
L'efficacité du BLT se manifeste particulièrement lors de la phase d'inférence, où l'on observe des réductions de calcul pouvant atteindre 50%. Cette optimisation s'explique notamment par la capacité du modèle à traiter des patches de taille variable, permettant de réduire le nombre d'opérations nécessaires sur les séquences prévisibles.
Mise à l’échelle
Contrairement aux architectures traditionnelles basées sur la tokenisation, qui allouent uniformément leurs ressources computationnelles, le BLT introduit en effet un paradigme plus flexible en permettant d'augmenter simultanément la taille du modèle et celle des patches tout en maintenant un budget d'inférence constant. Cette caractéristique distinctive permet non seulement une allocation plus judicieuse des ressources, où les patches plus longs permettent de réduire la charge computationnelle du transformateur latent global, mais elle ouvre également de nouvelles perspectives en termes d'efficacité. Les études démontrent que les modèles BLT, particulièrement ceux utilisant des patches de 6 à 8 octets, surpassent rapidement les performances des architectures conventionnelles comme LLaMA 2 et 3, tout en réduisant jusqu'à 50% les opérations nécessaires lors de l'inférence.
Cette efficacité accrue se manifeste de manière encore plus prononcée à grande échelle. En effet, alors que les tokenizers traditionnels de Llama 2 et 3 opèrent avec des tailles moyennes de token relativement modestes (3,7 et 4,4 octets respectivement), le BLT maintient des performances équivalentes ou supérieures avec des patches significativement plus grands, permettant une économie substantielle des ressources de calcul.
Cette caractéristique s'avère particulièrement pertinente dans un contexte d'augmentation de la taille des modèles et des données. Bien que les modèles BLT puissent initialement présenter des performances inférieures aux modèles basés sur la tokenisation à petite échelle, ils finissent par les surpasser de manière significative lorsque l'échelle augmente, suggérant un potentiel encore plus important pour les développements futurs.
Pour en savoir plus :
- Artidoro Pagnoni et al., Byte Latent Transformer: Patches Scale Better Than Tokens, Arxiv, 2024
- Meta
- The Decoder
- MarkTech Post