
Même alors que leurs dimensions semblent avoir atteint un plafond, les grands modèles de langage (LLM) progressent de manière significative, grâce aux raisonnements en chain-of-thought, mais la manière dont ils utilisent leurs ressources cognitives reste mal comprise.
Une étude récente, prépubliée par trois chercheurs de l’université de Bruxelles et de Harvard, compare plusieurs versions de ces modèles sur le benchmark Omni-Math afin de déterminer si l’amélioration de la performance provient d’une chaîne de raisonnement plus longue ou d’une utilisation plus efficace du calcul au moment de l'inférence. Les résultats indiquent que le modèle o3-mini (m) d’OpenAI, optimisé pour maximiser la précision avec un nombre modéré de tokens, surpasse o1-mini en précision sans nécessairement allonger son raisonnement. De plus, l’étude met en évidence une tendance générale : l’allongement du raisonnement s’accompagne d’une baisse de précision, même en contrôlant la difficulté des questions.
Efficacité du raisonnement et consommation de ressources
L’expérience compare les modèles gpt-4o, o1-mini, o3-mini (m) et o3-mini (h), une variante consommant plus de ressources pour un léger gain de précision, en les soumettant à 4 428 problèmes mathématiques de niveau olympiade issus du benchmark Omni-Math. Gpt-4o affiche les scores les plus bas, avec une précision oscillant entre 20 et 30 %, tandis que les modèles de raisonnement surpassent 50 % dans toutes les catégories. o1-mini progresse entre 40 % et 60 %, et o3-mini (m) améliore encore ces performances. o3-mini (h), bien qu’obtenant un léger gain de 4 % en précision par rapport à o3-mini (m), le fait en mobilisant significativement plus de tokens de raisonnement.
Les résultats montrent que l’augmentation du nombre de tokens de raisonnement tend à réduire la précision. Ce phénomène est plus marqué pour les modèles moins performants. Ainsi, o1-mini voit sa précision chuter rapidement au-delà de 12 000 tokens, alors que o3-mini (m) conserve une précision stable jusqu’à 30 000 tokens. o3-mini (h), bien que plus performant, utilise en moyenne deux fois plus de tokens qu'o3-mini (m) pour chaque question, ce qui suggère une optimisation moins efficace du raisonnement.
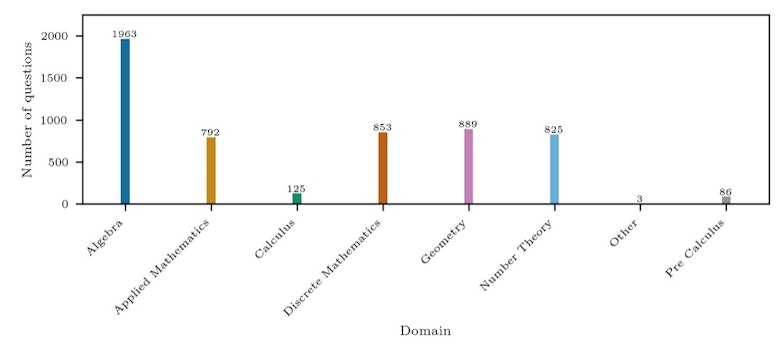
Distribution des domaines de l'ensemble de données Omni-Math • Source : Marthe Ballon et al.
La consommation de tokens varie selon le domaine mathématique. Les problèmes relevant de la géométrie et des mathématiques discrètes demandent plus de ressources que ceux d’algèbre ou de calcul. À difficulté égale, un usage excessif de tokens semble contre-productif. Une analyse régressive indique qu’en moyenne, l’ajout de 1 000 tokens fait chuter la précision de 3,16 % pour o1-mini, de 1,96 % pour o3-mini (m) et de 0,81 % pour o3-mini (h).
Optimisation des modèles de raisonnement
L’hypothèse selon laquelle un raisonnement plus long est nécessairement plus efficace est ainsi remise en question. o3-mini (m) surpasse o1-mini sans avoir besoin d’allonger sa chaîne de raisonnement. À l’inverse, o3-mini (h) obtient un gain de précision marginal tout en consommant beaucoup plus de ressources.
L’étude souligne la nécessité de nouvelles approches pour optimiser les modèles de raisonnement et améliorer leur évaluation, en s’appuyant sur une meilleure gestion des ressources et une réduction du raisonnement inutile. Les chercheurs suggèrent que limiter la longueur des chaînes de raisonnement pourrait être bénéfique pour les modèles les moins performants, évitant ainsi une utilisation inefficace des ressources. Ces conclusions ouvrent la voie à des modèles plus efficients, capables d’atteindre des performances élevées sans dépendre d’une augmentation excessive du nombre de tokens de raisonnement.
Les travaux futurs pourraient explorer des stratégies d’optimisation plus avancées, notamment en ajustant dynamiquement la longueur des chaînes de raisonnement en fonction du niveau de confiance du modèle sur une question donnée. Une telle approche permettrait de réduire la consommation de ressources tout en maximisant la précision. De plus, l’intégration d’un mécanisme d’évaluation interne des étapes de raisonnement pourrait aider à détecter et à corriger les erreurs avant la génération de la réponse finale, améliorant ainsi l’efficacité globale des modèles de raisonnement avancés.
Reformuler les prompts
Une autre piste de recherche concerne l’impact de la formulation des questions sur la performance des modèles. Certaines études suggèrent que des reformulations spécifiques peuvent conduire à des résultats plus précis avec un raisonnement moins coûteux en ressources. Tester systématiquement ces reformulations et identifier les structures les plus efficaces pourraient constituer une avancée significative dans l’optimisation des modèles d’intelligence artificielle dédiés au raisonnement logique et mathématique.
Enfin, la question de l’évaluation reste centrale. L’actuel benchmark Omni-Math offre un cadre structuré, mais pourrait être enrichi par de nouveaux jeux de tests intégrant des scénarios plus variés et proches des applications réelles des LLM. L’introduction de métriques plus fines permettant d’évaluer, non seulement la justesse des réponses, mais aussi leur coût computationnel, offrirait une vision plus complète des capacités des modèles et des compromis qu’ils impliquent entre précision et consommation de ressources.
Pour en savoir plus :
- Marthe Ballon et al., The Relationship Between Reasoning and Performance in Large Language Models -- o3 (mini) Thinks Harder, Not Longer, Arxiv, 2025