
Vendredi, le modèle R1 de la chinoise DeepSeek a brièvement pris la tête du très reconnu classement LMSYS Arena Leaderboard, devant Gemini 2.0 Flash et ChatGPT-4o. C’était la première fois qu’un modèle open source (avec poids ouverts) occupait ce rang ; peu s’attendaient à ce que s’ensuive la tempête boursière d’hier.
Le modèle qui pense en plusieurs langues, et en code
La start-up de Hangzhou, voisine d’Alibaba, est arrivée à ce résultat en misant tout sur l’apprentissage par renforcement, sans feedback humain. DeepSeek-R1-Zero développe des capacités de raisonnement uniquement à l’aide de l’apprentissage par renforcement, sans recours à des données supervisées. Le modèle est conçu pour évaluer et affiner ses propres réponses, aussi bien en termes de contenu que de format. cela a permis l’émergence de comportements complexes et avancés en matière de raisonnement.
L’entraînement de R1-Zero utilise un algorithme de reinforcement learning innovant, basé sur l’optimisation relative de politiques de groupe (GRPO). Contrairement aux approches traditionnelles nécessitant un modèle critique de taille équivalente, cette méthode évalue les réponses en fonction de groupes de résultats, permettant ainsi de réduire significativement les coûts d’entraînement.
Conçu pour penser
Tout comme AlphaGo, avec cette méthode, a trouvé un coup hétérodoxe qui lui a permis de devenir champion du monde, R1-Zero développe des chain-of-thought étonnantes, mêlant plusieurs langues et du code informatique pour parvenir à des réponses parfois très originales, mais souvent confuses, répétitives et peu lisibles.
DeepSeek-R1, en conséquence, a été conçu spécifiquement pour ses capacités de raisonnement. Il utilise une méthode d’apprentissage par renforcement multi-étapes, combinée à des données de départ (« cold-start ») et un ajustement supervisé.
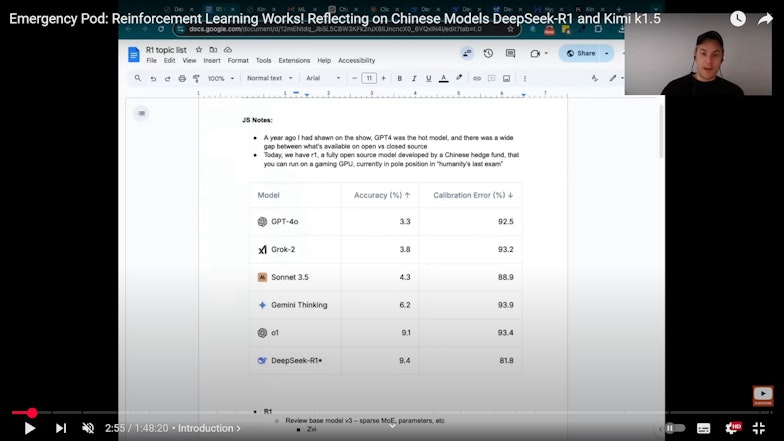
Une des particularités de R1 est la transparence dans ses raisonnements grâce à l’inclusion de chaînes de raisonnement explicites. Cette approche permet non seulement de comprendre les étapes intermédiaires de réflexion, mais aussi d’assurer des performances comparables à celles de modèles propriétaires tels qu’OpenAI o1-1217, tout en étant plus accessible en termes de coûts d’utilisation.
Distillation et autoreproduction
La connaissance acquise par R1-Zero a été “distillée” dans R1 : l’ancien modèle a été utilisé pour entraîner le nouveau. Même si la start-up ne l’admet pas officiellement, il est probable que d’autres modèles du marché ont également été utilisés dans ce but.
On voit ici se rapprocher le point d’échappée, fort redouté, où des super-intelligences artificielles (ASI) seront capables d’en entraîner d’autres. Mais dans l’immédiat, il a surtout pour effet d’accélérer la convergence des performances des modèles, chacun apprenant sans doute de l’autre.
DeepSeek peut ainsi réduire la taille de ses modèles tout en conservant leurs performances pour un type de raisonnement particulier. Les versions distillées de R1, disponibles dans des tailles allant de 1,5 à 70 milliards de paramètres, ont été conçues pour répondre à des besoins spécifiques : environnements contraints en ressources, applications nécessitant une faible latence ou modèles intégrés dans des systèmes embarqués.
Par exemple, la version distillée de 14 milliards de paramètres dépasse plusieurs modèles de référence en matière de raisonnement mathématique et en traitement des tâches codées.
Gestion de la mémoire
La principale innovation de DeepSeek, cependant, consiste dans la gestion de la mémoire nécessaire pour l’inférence. Pour qu’un modèle d’IA génère une réponse, en effet, il est nécessaire de le charger en mémoire, lui, et aussi la fenêtre de contexte. Celle-ci est particulièrement gourmande, car chaque jeton (token) requiert une clé et une valeur associée.
Depuis son deuxième modèle ((lire Qant du 16 janvier 2024), DeepSeek a mis au point une fenêtre d’attention baptisée MLA (pour multi-head latent attention) qui diminue considérablement la dimension du cache qui contient les clés et les valeurs. C’est là ce qui lui permet de réduire les coûts d’inférence de presque 30 fois par rapport au marché.
Conséquences inattendues
Les restrictions sur les exportations technologiques américaines, censées ralentir les avancées chinoises, ont ainsi poussé DeepSeek et d’autres acteurs locaux à optimiser leurs procédés pour compenser le manque de ressources de pointe.
DeepSeek MLA a été mise au point pour contourner les limitations des H-800, les puces bridées que Nvidia était contrainte de vendre en Chine. Les concurrents américains de la start-up chinoise n’avait pas besoin d’être ingénieux ; il leur suffisait d’attendre la génération suivante de GPU pour voir la puissance de leurs modèles augmenter.
Reste la grande incertitude des modèles open source : la solidité de leur alignement – ce que montre bien, par exemple, GhostGPT (voir ci-dessus). Dans le cas de R1, l’absence d’apprentissage supervisé pour le modèle précurseur R1-Zero rend le sujet particulièrement sensible.
Pour en savoir plus :
- Daya Guo et al., DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, Arxiv, 2025
- Aixin Liu et al, DeepSeek-V3 Technical Report, 2024, Arxiv
- Maciej Besta, Reasoning Language Models: A Blueprint, Arxiv, 2025
- Gary Marcus
- Perplexity
- MIT
- Wall Street Journal
- Bloomberg